Hi, I'm Nithin Sai Jalukuru.
A
Energetic programmer with a relentless drive for problem-solving. Passionate about unraveling complex real-world challenges, I thrive on the thrill of finding innovative solutions.
About
Dive into the world of Nithin Sai Jalukuru, where data transforms into actionable insights and innovation knows no bounds. From orchestrating cutting-edge AI chatbots to pioneering the future of data analysis at global conglomerates, Nithin's journey has been nothing short of extraordinary. With a potent blend of technical expertise from the University at Buffalo and hands-on experience spanning continents, he is on a relentless pursuit to harness the power of data and reshape industries. Whether it's predicting risk genes in autism or forecasting the future of AI, Nithin's work stands as a testament to his unparalleled skillset and unwavering passion. Welcome to a realm where data meets destiny, and every byte tells a story.
- Languages: Python (Data science Libraries) , R, Java, C, SQL, HTML/CSS, Bash
- Databases: MySQL, PostgreSQL, Cassandra
- Cloud: Google Cloud Platform(Looker, BigQuery), Azure, Heroku
- Frameworks: Tableau, Excel, Apache Airflow, Apache Kafka, Apache Spark, Kanban, ServiceNow, Git
- Tools & Technologies: Flask, Keras, Pytorch, DataBricks ,Hadoop, Hive, TensorFlow, Scikit-learn, Streamlit, Folium, Pydeck, Heroku.
I am a data scientist with a passion for using my skills to solve real-world problems. I can unlock your company's data potential with my expertise, unleashing valuable insights and driving data-driven strategies for success.
Experience

- Spearheaded the enhancement of the SFR application for ILSOS as the sole developer, improving system functionality and streamlining processes.
- Enhanced compliance and efficiency by refining electronic SR22/26 files for high-risk insurance (File transfers from Insurance companies) ; ensured accurate FTP transfers and regulatory adherence using UNIX and mainframe systems.
- Developed and implemented a nightly batch program to comply with FMCSA’s Drug and Alcohol Clearinghouse mandate, while also creating backend functionality for the driver’s facility application.
- Automated data refresh processes using stored procedures, reducing manual effort by hours and increasing efficiency.
- Designed and executed data analytics reports using SSRS and Power BI, extracting key insights from driving test data to inform strategic decisions and policy development.
- Led a data purging initiative using advanced SQL and Azure Databricks to process millions of driving license records, en-hancing database performance and data processing capabilities within 3 months and enabling advanced analytics.
- Contrator for ILSOS , Employers : VistalTech Inc (Sept 2023 - May 2024), MSR Technology Group LLC (June 2024 - Current)

- Spearhead a data research analyst team, conducting comprehensive assessments and analyses of energy-related data.
- Employ advanced statistical models and visualization techniques to uncover trends, patterns, and insights within extensive datasets, encompassing energy consumption, renewable sources, and environmental impact.
- Collaborate extensively with energy experts, policymakers, and community stakeholders, translating data insights into actionable recommendations for optimizing energy efficiency and fostering sustainable practices. Tools: Python, SQL, Excel, Selenium, Node.JS, Data visualization, Databases

- Collaborated with professor in developing assessments and projects, while providing ongoing guidance and support to 150+ students throughout the coursework (Fundamentals of Computational Science), resulting in enhanced learning outcomes and academic success.
- Facilitated Weekly Office Hours to address student inquiries and clarify any doubts in solving Assessment’s (Python) and Projects.
- Professor: Dr. Han Daozhi , UB Mathematics Dept, Course: CDA 511, Fundamentals of Computational Sciences
- Conducted data analysis using BigQuery, performing complex SQL queries and advanced analytical functions on datasets of up to 100 million records, uncovering actionable insights for business decisions.
- Developed data pipelines and ETL processes using GCP services such as Dataflow and Cloud Storage, automating data ingestion, transformation, and loading into BigQuery, resulting in a 50% reduction in data processing time.
- Collaborated with cross-functional teams to understand business requirements, delivering data models and analytical solutions that improved operational efficiency and drove a 15% increase in revenue.
- Developed custom data visualizations and dashboards using Data Studio (Looker),Python libraries (such as Matplotlib, Seaborn, or Plotly) and tools like Data Studio, presenting complex data analysis results to 50+ stakeholders in actionable manner.
- Designed and optimized data models in BigQuery, implementing schema design, partitioning, and clustering strategies, resulting in a 30% improvement in query performance and a 20% reduction in storage costs.
- Documented data analysis methodologies, processes, and findings creating 20+ comprehensive reports for stakeholders .
- Tools: GCP, BigQuery, Python, SQL, Excel, ServiceNow, Data visualization, Databases
- Demonstrated expertise in Caculus by providing accurate and comprehensive solutions to student questions on the Chegg platform.
- Maintained a high customer satisfaction rating by delivering prompt and insightful responses to student inquiries, fostering a positive learning experience.
- Subject: Engineering Mathematics (calculus)

- Analyzed clients data sets using Python libraries, SQL queries, and Tableau to create interactive dashboards.
- Developed and implemented machine learning models to solve complex business problems.
- Conducted exploratory data analysis on large datasets to identify patterns and trends.
- Implemented data validation checks, reducing data entry errors by 30% and enhancing overall data quality. Tools: Python (Pandas, Numpy,Matplotlib, Seaborn), SQL, Tableau, Statistics
- Leveraged advanced programming skills in CNC (Computer Numerical Control) to develop and optimize precise machining instructions for a critical component in the Akash missile using a turn mill center.
- Applied data analysis techniques to evaluate and refine machining parameters, ensuring optimal efficiency, accuracy, and quality in the production process.
- Utilized statistical methods and process control techniques to identify and address potential sources of variation, minimizing defects and enhancing overall product performance and reliability.
- Documented programming methodologies, process parameters, and best practices, creating a knowledge repository to support future production and maintenance activities.
- Tools: CNC programming (G, M codes), ANOVA, Taguchi DOE, Excel
Projects

NewYork City collision Analysis web-app on GCP BigQuery and Streamlit.
- Tech Stack: Python, Streamlit, PyDeck, Folium, Google Cloud Platform, BigQuery, SQL, Looker Studio,Heroku
- Extracted NYC collision data (~ 2 Million Rows) from NYC Open Data
- Analysed it using GCP BigQuery SQL.
- Visualized the results with Looker Studio dashboards
- Built a web application with Streamlit to share the actionable insights
- Deployed in Heroku.

Forecasting Risk Gene discovery in Autism with Genome Scale Data

Data Scientist Salary prediction (Python, SQL,ML Algo's )
- Tech Stack:Python ( Pandas, NumPy, Panda’s profiling, Plotly, Sqlite3, Scikit-Learn), SQL, MySQL
- Collected, cleaned, and normalized data from Kaggle for data scientist job postings
- Stored it in a SQLite3 database. Analysed data by using complex visualizations to draw conclusions.
- Implemented Ridge regression, Lasso regression, Naïve Bayes and SVM to model .
Covered variety of projects on different machine learning Algorithms
- Life Expectancy Prediction Models Used : Linear, Logistic and Decision Tree Machine Learning Models.
- Implementation of Backpropagation Neural Network in classification of Diabetes
- Gausian Mixture for Smart Grid Stability Prediction
- Penguin Species classification using SVM
- Implementation of Naïve Bayes Classifier on Income Classification
- Implementation of Adaptative Boosting (AdaBoost) for the detecting Alzheimer’s at early stage
- Implementation of Convolutional Autoencoding in Brain Tumor MRI Scan Images
- A Case Study with implementation of Hidden Markov Model (HMM)
- An approach for the prediction of water quality using Random Decision Forest model

Highway Traffic Data Integration and Real-time Streaming Pipeline for Toll Plaza Analysis
- Tech Stack : Apache Airflow, Bash, Apache Kafka, Zookeeper , Simulators, Python, DAG’s
- Developed and implemented a data pipeline using Apache Airflow to download, extract, transform, and consolidate data from various file formats with DAG definition, data extraction, transformation, and pipeline submission
- Configured and managed a streaming data pipeline using Apache Kafka, including setting up Zookeeper, starting Kafka server, creating a topic, downloading, and configuring the Toll Traffic Simulator
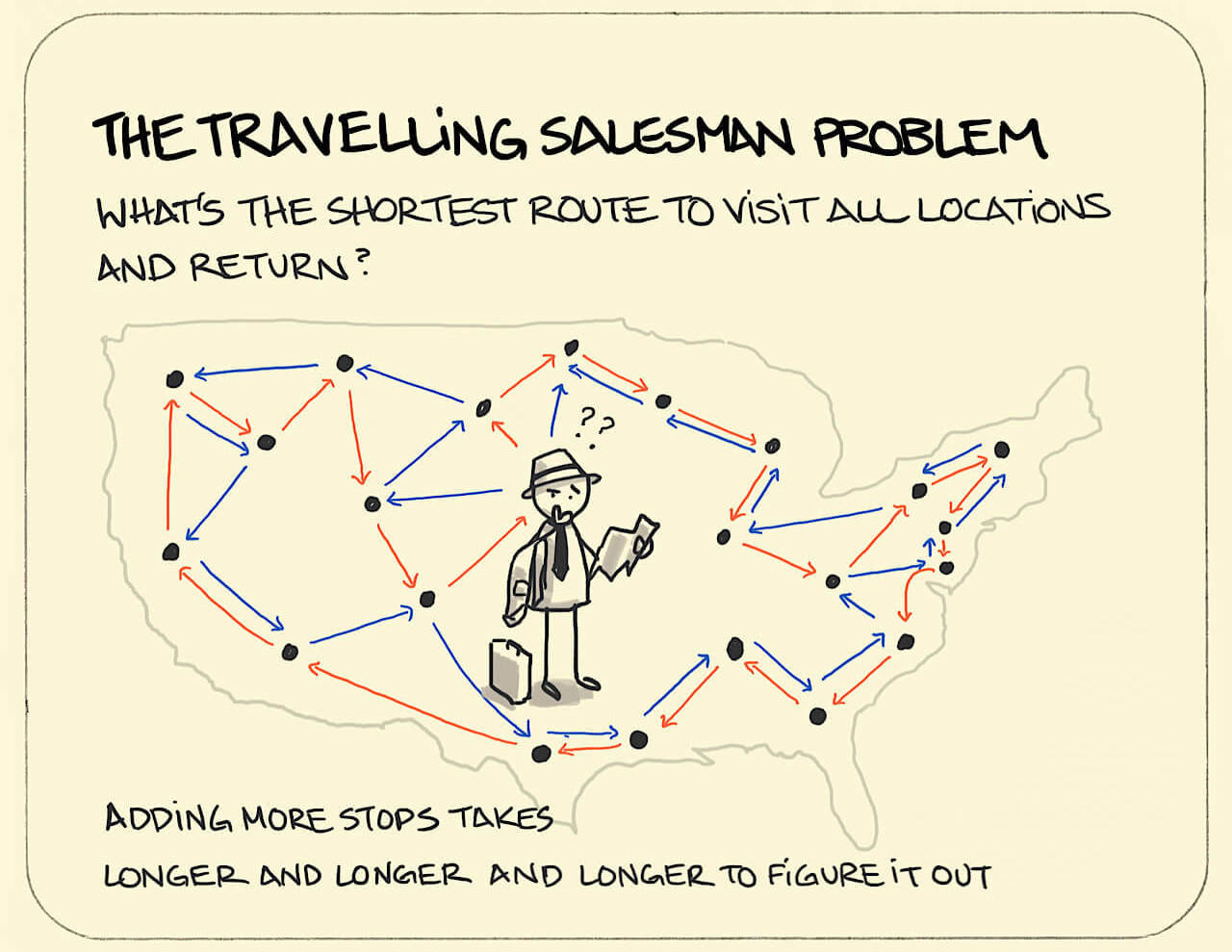
Solved by utilizing ML models to determine the shortest path for given number of locations
- Leveraged the Nearest Neighbors algorithm to compute pairwise distances, mitigating computational infeasibility of exhaustive permutation generation for large-scale Traveling Salesman Problem (TSP) instances.
- Implemented Nominatim API integration for dynamic retrieval of city coordinates, eliminating manual data entry, and employed GIF-based animated tour generation to offer an engaging and interactive visualization of the optimal route in a technical context.
Skills
Languages and Databases
 R
R
 Java
Java
 MATLAB
MATLAB
Libraries
 Seaborn
Seaborn
 Pydeck
Pydeck
 ImageIO
ImageIO
 GeoPy
GeoPy
 Folium
Folium
Frameworks
 AirFlow
AirFlow
 Kafka
Kafka
 Spark
Spark
Other
 Git
Git
 AWS
AWS
 Heroku
Heroku
 Databricks
Databricks
 Tableau
Tableau
Education
Buffalo, NY, USA
Degree: Master of Science in Computer Science
CGPA: 4.0/4.0
- Database management Systems
- Probability and Statistics
- Data Mining in R (Supervised and Unsupervised)
- Machine Learning
- Data Structures Algorithms
Relevant Courseworks:
Hyderabad, Telangana, India
Degree: Bachelor's and Master's in Mechanical Engineering
CGPA: 9.5/10
- Optimization Techniques
- Statistical Learning
- Advanced Manufacturing Systems
- Data Analysis
- Design of Machine Elements
Relevant Courseworks: